



































spark基础知识介绍

Spark是一种开源集群计算环境,与Hadoop相似但又有所不同。Apache Spark最初是由加州大学伯克利分销的AMP实验室开发出来的,后来成为Apache的开源项目之一,作为专门为大规模数据处理而设计的快速通用型计算引擎来使用。与MapReduce技术相比,Spark有着多种优势,如提供了统一全面的框架、大大提高了应用运行速度、可以快速使用Java等语言来编写程序等,目前Spark形成一个应用广泛、发展高速的生态系统。接下来就让我们一起来了解下Spark的性能特点、运行模式、运行特点以及体系架构等知识。
目录
1. spark性能特点
2. spark运行模式
3. spark运行特点
4. spark体系架构
5. spark与hadoop的关系
-

spark性能特点
1、专注性。由于高级API剥离了对于集群本身的关注,所以spark开发者可以专注于应用所需要做的计算本身。
2、速度快。Spark支持复杂算法和交互式计算,运行速度快。
3、通用性。Spark是一个通用引擎,因此可以用来完成如文本处理、SQL查询等运算。
4、支持多种资源管理器。如Hadoop YARN、Apache Mesos等管理器都支持使用。 -

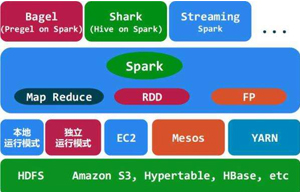
spark运行模式
1、spark的运行模式是多种多样的,并不限于一种,可以按需选择。
2、以单机方式部署时,spark可以用本地模式运行或者伪分布模式运行。
3、部署在分布式集群时,也可以根据集群的实际选择不同的运行模式。底层资源调度既可以使用spark內建的独立集群运行模式,也可以依赖外部资源调度框架。 -
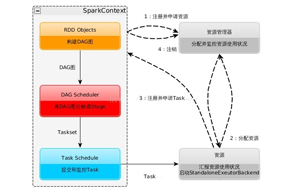
spark运行特点
1、除非在外部存储系统写入数据,否则Spark Application就不能跨应用共享数据。
2、spark的运行和资源管理器是没有关系的,只需获取executor进程并保持通信即可。
3、提交SparkContext的Client需靠近运行Executor的节点,而且最好在同一个Rack里。
4、Task采用的优化机制是数据本地性和准侧执行。 -
spark体系架构
Spark体系架构主要有三个组件。
1、数据存储。Spark使用HDFS文件系统来存储数据。
2、资源管理。Spark有多种不同的部署方式,可以部署在一个单独服务器上,也可以部署在分布式计算框架上,如Mesos等。
3、API。Spark提供三种程序设计语言的API,分别是Java、Scala和Python。开发者可以利用标准的API接口来创建基于Spark的应用。 -

spark与hadoop的关系
1、spark自身是没有提供分布式文件系统的,其分析大部分都需要依赖于Hadoop的分布式文件系统,也就是HDFS。
2、Mapreduce是Hadoop的分布式计算模块,Mapreduce和spark都可以计算数据,但Mapreduce比spark速度要慢一些,且功能也不如spark丰富。
3、spark可以看作是Hadoop MapReduce的替代品,用来提供一个全面、统一的管理大数据用例和需求的解决方案。





- 关于cms系统设计的小知识
- 中企动力提醒:网络违法案例,等保刻不容缓
- 中企动力:网站运营怎么做之统计后台篇
- 中企动力:网站运营难不难?
- 中企动力在5G时代给企业的小建议
- 中企动力:个人建站需要哪些能力?
- 中企动力:公司网站被黑怎么办?
- 中小企业数字经济论坛召开,中企动力助力企业数字化转型
- 中企动力:教你如何建立“新型”企业网站
- 肉驴养殖利润效益分析
- 在线建网站靠谱吗?在线建网站常问的5个问题!
- 营销广告人员必看,市场分析包括哪些方面?
- 揭秘:在线建网站内幕曝光,80%老板都被骗了
- 优秀的广告设计理念需要具备的基本要素
- 广告联盟的特点
- 数据库在建立信息管理系统中的特点
- 抖音和今日头条的关系浅析
- 你真的会写品牌推广计划吗?
- 你了解linux运维工程师吗
- 微信推广平台如何起到良好的宣传作用





